Tutorial: Inserting Records and DataFrames Into a SQL Database
Learn to insert data into SQL databases like a pro!
One of the key roles of a data scientist is to extract patterns and insights from raw data. Since much of the world’s government and corporate data is organized in relational databases, it makes sense that data scientists need to know how to work with these database structures. Writing SQL queries to insert, extract, and filter data in databases is a key skill for anyone interested in data analytics or data science.
SQL (Structured Query Language) is based on E. F. Codd’s Relational model and algebra to manage the relational databases. It’s a database query language used to create, insert, query, and manipulate the relational database and used by a large number of applications.
Although it has been around for decades, learning SQL is still a critical skill for modern data scientists, and really anyone who works with data at all, because SQL is used in all kinds of relational database software, including MySQL, SQL Server, Oracle, and PostgreSQL.
In this tutorial, we’ll learn about SQL insertion operations in detail. Here is the list of topics that we will learn in this tutorial:
- SQL Insertion
- Inserting records into a database
- Inserting Pandas DataFrames into a database using the insert command
- Inserting Pandas DataFrames into a database using the to_sql() command
- Reading records from a database
- Updating records in a database
Want to reach a higher level of SQL skill? Sign up for free and check out Dataquest’s SQL courses for thorough, interactive lessons on all the SQL skills you’ll need for data science.
SQL Insertion
SQL Insertion is an essential operation for data workers to understand. Inserting missing data or adding new data is a major part of the data cleaning process on most data science projects.
Insertion is also how most data gets into databases in the first place, so it’s important anytime you’re collecting data, too. When your company gets new data on a customer, for example, chances are than a SQL insert will be how that data gets into your existing customer database.
In fact, whether or not you’re aware of it, data is flowing into databases using SQL inserts all the time! When you fill out a marketing survey, complete a transaction, file a government form online, or do any of thousands of other things, your data is likely being inserted into a database somewhere using SQL.
Let’s dive into how we can actually use SQL to insert data into a database. We can insert data row by row, or add multiple rows at a time.
Inserting records into a database
In SQL, we use the INSERT command to add records/rows into table data. This command will not modify the actual structure of the table we’re inserting to, it just adds data.
Let’s imagine we have a data table like the one below, which is being used to store some information about a company’s employees.
Now, let’s imagine we have new employees we need to put into the system.
This employee table could be created using the CREATE TABLE command, so we could use that command to create an entirely new table. But it would be very inefficient to create a completely new table every time we want to add data! Instead, let’s use the INSERT command to add the new data into our existing table.
Here’s the basic syntax for using INSERT in SQL:
We start with the command INSERT INTO followed by the name of table into which we’d like to insert data. After the table name, we list the columns of new data we're inserting column by column, inside parentheses. Then, on the next line, we used the command VALUES along with the values we want to insert (in sequence inside parentheses.
So for our employee table, if we were adding a new employee named Kabir, our INSERT command might look like this:
Inserting Records Into a Database From Python
Since we’re often working with our data in Python when doing data science, let’s insert data from Python into a MySQL database. This is a common task that has a variety of applications in data science.
We can send and receive data to a MySQL database by establishing a connection between Python and MySQL. There are various ways to establish this connection; here, we will use pymysql for database connectivity.
Here are the broad steps we’ll need to work through to get pymysql connected, insert our data, and then extract the data from MySQL:
Let’s walk through this process step by step.
Step 1: Import the pymysql module.
# Import pymysql module
import pymysqlStep 2: Create connection a to the MySQL database
Create a connection using pymysql‘s connect() function with the parameters host, user, database name, and password.
(The parameters below are for demonstration purposes only; you’ll need to fill in the specific access details required for the MySQL database you’re accessing.)
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')Step 3: Create a cursor using the cursor() function.
This will allow us to execute the SQL query once we’ve written it.
cursor = connection.cursor()Step 4: Execute the required SQL query
Commit the changes using the commit() function, and check the inserted records. Note that we can create a variable called sql, assign our query’s syntax to it, and then pass sql and the specific data we want to insert as arguments to cursor.execute().
Then, we’ll commit these changes using commit().
# Create a new record
sql = "INSERT INTO employee (EmployeeID, Ename, DeptID, Salary, Dname, Dlocation) VALUES
# Execute the query
cursor.execute(sql, (1008,'Kabir',2,5000,'IT','New Delhi'))
# the connection is not autocommited by default. So we must commit to save our changes.
connection.commit()Let’s do a quick check to see if the record we wanted to insert has actually been inserted.
We can do this by querying the database for the entire contents of employee, and then fetching and printing those results.
# Create a new query that selects the entire contents of employee
sql = "SELECT * FROM employee"
cursor.execute(sql)
# Fetch all the records and use a for loop to print them one line at a time
result = cursor.fetchall()
for i in result:
print(i)(1001, 'John', 2, 4000, 'IT', 'New Delhi')
(1002, 'Anna', 1, 3500, 'HR', 'Mumbai')
(1003, 'James', 1, 2500, 'HR', 'Mumbai')
(1004, 'David', 2, 5000, 'IT', 'New Delhi')
(1005, 'Mark', 2, 3000, 'IT', 'New Delhi')
(1006, 'Steve', 3, 4500, 'Finance', 'Mumbai')
(1007, 'Alice', 3, 3500, 'Finance', 'Mumbai')
(1008, 'Kabir', 2, 5000, 'IT', 'New Delhi')It worked! Above, we can see the new record has been inserted and is now the final row in our MySQL database.
Step 5: Close the database connection
Now that we’re done, we should close the database connection using close() method.
# Close the connection
connection.close()Of course, it would be better to write this code in a way that could better handle exceptions and errors. We can do this using try to contain the body of our code and except to print errors if any arise. Then, we can use finally to close the connection once we’re finished, regardless of whether try succeeded or failed.
Here’s what that looks like all together:
import pymysql
try:
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')
cursor=connection.cursor()
# Create a new record
sql = "INSERT INTO employee (EmployeeID, Ename, DeptID, Salary, Dname, Dlocation) VALUES
cursor.execute(sql, (1009,'Morgan',1,4000,'HR','Mumbai'))
# connection is not autocommit by default. So we must commit to save our changes.
connection.commit()
# Execute query
sql = "SELECT * FROM employee"
cursor.execute(sql)
# Fetch all the records
result = cursor.fetchall()
for i in result:
print(i)
except Error as e:
print(e)
finally:
# close the database connection using close() method.
connection.close()((1001, 'John', 2, 4000, 'IT', 'New Delhi'), (1002, 'Anna', 1, 3500, 'HR', 'Mumbai'), (1003, 'James', 1, 2500, 'HR', 'Mumbai'), (1004, 'David', 2, 5000, 'IT', 'New Delhi'), (1005, 'Mark', 2, 3000, 'IT', 'New Delhi'), (1006, 'Steve', 3, 4500, 'Finance', 'Mumbai'), (1007, 'Alice', 3, 3500, 'Finance', 'Mumbai'), (1008, 'Kabir', 2, 5000, 'IT', 'New Delhi'), (1009, 'Morgan', 1, 4000, 'HR', 'Mumbai'), (1009, 'Morgan', 1, 4000, 'HR', 'Mumbai'))Inserting Pandas DataFrames Into Databases Using INSERT
When working with data in Python, we’re often using pandas, and we’ve often got our data stored as a pandas DataFrame. Thankfully, we don’t need to do any conversions if we want to use SQL with our DataFrames; we can directly insert a pandas DataFrame into a MySQL database using INSERT.
Once again, we’ll take it step-by-step.
Step 1: Create DataFrame using a dictionary
We could also import data from a CSV or create a DataFrame in any number of other ways, but for the purposes of this example, we’re just going to create a small DataFrame that saves the titles and prices of some data science texbooks.
# Import pandas
import pandas as pd
# Create dataframe
data = pd.DataFrame({
'book_id':[12345, 12346, 12347],
'title':['Python Programming', 'Learn MySQL', 'Data Science Cookbook'],
'price':[29, 23, 27]
})
data| book_id | title | price | |
|---|---|---|---|
| 0 | 12345 | Python Programming | 29 |
| 1 | 12346 | Learn MySQL | 23 |
| 2 | 12347 | Data Science Cookbook | 27 |
Step 2: Create a table in our MySQL database
Before inserting data into MySQL, we’re going to to create a book table in MySQL to hold our data. If such a table already existed, we could skip this step.
We’ll use a CREATE TABLE statement to create our table, follow that with our table name (in this case, book_details), and then list each column and its corresponding datatype.

Step 3: Create a connection to the database
Once we’ve created that table, we can once again create a connection to the database from Python using pymysql.
import pymysql
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='book')
# create cursor
cursor=connection.cursor()Step 4: Create a column list and insert rows
Next, we’ll create a column list and insert our dataframe rows one by one into the database by iterating through each row and using INSERT INTO to insert that row’s values into the database.
(It is also possible to insert the entire DataFrame at once, and we’ll look at a way of doing that in the next section, but first let’s look at how to do it row-by-row).
# creating column list for insertion
cols = ",".join([str(i) for i in data.columns.tolist()])
# Insert DataFrame recrds one by one.
for i,row in data.iterrows():
sql = "INSERT INTO book_details (" +cols + ") VALUES (" +
cursor.execute(sql, tuple(row))
# the connection is not autocommitted by default, so we must commit to save our changes
connection.commit()Step 5: Query the database to check our work
Again, let’s query the database to make sure that our inserted data has been saved correctly.
# Execute query
sql = "SELECT * FROM book_details"
cursor.execute(sql)
# Fetch all the records
result = cursor.fetchall()
for i in result:
print(i)(12345, 'Python Programming', 29)
(12346, 'Learn MySQL', 23)
(12347, 'Data Science Cookbook', 27)Once we’re satisfied that everything looks right, we can close the connection.
connection.close()Inserting Pandas DataFrames into a Database Using the to_sql() Function
Now let’s try to do the same thing — insert a pandas DataFrame into a MySQL database — using a different technique. This time, we’ll use the module sqlalchemy to create our connection and the to_sql() function to insert our data.
This approach accomplishes the same end result in a more direct way, and allows us to add a whole dataframe to a MySQL database all at once.
# Import modules
import pandas as pd
# Create dataframe
data=pd.DataFrame({
'book_id':[12345,12346,12347],
'title':['Python Programming','Learn MySQL','Data Science Cookbook'],
'price':[29,23,27]
})
data| book_id | title | price | |
|---|---|---|---|
| 0 | 12345 | Python Programming | 29 |
| 1 | 12346 | Learn MySQL | 23 |
| 2 | 12347 | Data Science Cookbook | 27 |
Import the module sqlalchemy and create an engine with the parameters user, password, and database name. This is how we connect and log in to the MySQL database.
# import the module
from sqlalchemy import create_engine
# create sqlalchemy engine
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="12345",
db="employee"))Once we’re connected, we can export the whole DataFrame to MySQL using the to_sql() function with the parameters table name, engine name, if_exists, and chunksize.
We’ll take a closer look at what each of these parameters refers to in a moment, but first, take a look at how much simpler it is to insert a pandas DataFrame into a MySQL database using this method. We can do it with just a single line of code:
# Insert whole DataFrame into MySQL
data.to_sql('book_details', con = engine, if_exists = 'append', chunksize = 1000)Now let’s take a closer look at what each of these parameters is doing in our code.
book_detailsis the name of table into which we want to insert our DataFrame.con = engineprovides the connection details (recall that we created engine using our authentication details in the previous step).if_exists = 'append'checks whether the table we specified already exists or not, and then appends the new data (if it does exist) or creates a new table (if it doesn’t).chunksizewrites records in batches of a given size at a time. By default, all rows will be written at once.
Reading Records from a Database
Once we’ve used SQL inserts to get our data into the database, we’ll want to be able to read it back! So far in this tutorial, we’ve checked our SQL inserts by simply printing the entire database, but obviously this is not a viable option with larger databases where you’d be printing thousands of rows (or more). So let’s take a more in-depth look at how we can read back the records we’ve created or inserted into our SQL database.
We can read records from a SQL database using the SELECT command. We can select specific columns, or use * to select everything from a given table. We can also select to return only records that meet a particular condition using the WHERE command.
Here’s how the syntax for these commands looks:

We start with a SELECT clause, followed by list of columns, or * if we want to select all columns.Then we’ll use a FROM clause to name the table we’d like to look at. WHERE can be used to filter the records and followed by a filter condition, and we can also use ORDER BY to sort the records. (The WHERE and ORDER BY clauses are optional).
With larger databases, WHERE is useful for returning only the data we want to see. So if, for example, we’ve just inserted some new data about a particular department, we could use WHERE to specify the department ID in our query, and it would return only the records with a department ID that matches the one we specified.
Compare, for example, the results of these two queries using our employee table from earlier. In the first, we’re returning all the rows. In the second, we’re getting back only the rows we’ve asked for. This may not make a big difference when our table has seven rows, but when you’re working with seven thousand rows, or even seven million, using WHERE to return only the results you want is very important!
If we want to do this from within Python, we can use the same script we used earlier in this tutorial to query these records. The only difference is that we’ll tell pymysql to execute the SELECT command rather than the INSERT command we used earlier.
# Import module
import pymysql
# create connection
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')
# Create cursor
my_cursor = connection.cursor()
# Execute Query
my_cursor.execute("SELECT * from employee")
# Fetch the records
result = my_cursor.fetchall()
for i in result:
print(i)
# Close the connection
connection.close()(1001, 'John', 2, 4000, 'IT', 'New Delhi')
(1002, 'Anna', 1, 3500, 'HR', 'Mumbai')
(1003, 'James', 1, 2500, 'HR', 'Mumbai')
(1004, 'David', 2, 5000, 'IT', 'New Delhi')
(1005, 'Mark', 2, 3000, 'IT', 'New Delhi')
(1006, 'Steve', 3, 4500, 'Finance', 'Mumbai')
(1007, 'Alice', 3, 3500, 'Finance', 'Mumbai')
(1008, 'Kabir', 2, 5000, 'IT', 'New Delhi')
(1009, 'Morgan', 1, 4000, 'HR', 'Mumbai')
(1009, 'Morgan', 1, 4000, 'HR', 'Mumbai')Above, we’ve selected and printed the entire database, but if we wanted to use WHERE to make a more careful, limited selection, the approach is the same:
my_cursor.execute("SELECT * FROM employee WHERE DeptID=2")Updating Records in the Database
Often, we’ll need to modify the records in the table after creating them.
For example, imagine that an employee in our employee table got a promotion. We’d want to update their salary data. The INSERT INTO command won’t help us here, because we don’t want to add an entirely new row.
To modify existing records in the table, we need to use the UPDATE command. UPDATE is used to change the contents of existing records. We can specify specific columns and values to change using SET, and we can also make conditional changes with WHERE to apply those changes only to rows that meet that condition.
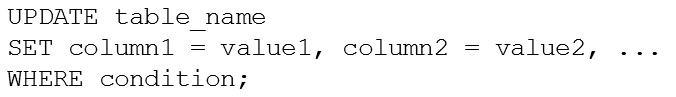
Now, let’s update the records from our employee table and display the results. In this case, let’s say David got the promotion — we’ll write a query using UPDATE that sets Salary to 6000 only in columns where the employee ID is 1004 (David’s ID).
Be careful — without the WHERE clause, this query would update every record in the table, so don’t forget that!
After executing the above query, the updated table would look like this:
Conclusion
In this tutorial, we’ve taken a look at SQL inserts and how to insert data into MySQL databases from Python. We also learned to insert Pandas DataFrames into SQL databases using two different methods, including the highly efficient to_sql() method.
Of course, this is just the tip of the iceberg when it comes to SQL queries. If you really want to become a master of SQL, sign up for free and dive into one of Dataquest’s interactive SQL courses to get interactive instruction and hands-on experience writing all the queries you’ll need to do productive, professional data science work.
Also check out some of our other free SQL-related resources: